



🤖 Data Explained: Retrieval Augmented Generation (RAG)
If you build RAG with a DAG, it can be a real DRAG

😅 Shenanigans
Before we get all serious, I need to make an observation— as a data nerd, I was always perplexed at why a simple concept has the acronym DAG (Directed Acyclic Graph).
Now, with the GenAI boom, I can wonder the same thing about RAG (Retrieval Augmented Generation).
These complicated acronyms are a real DRAG. Highly serious and technical business requires highly serious, technical acronyms. /s
Ok, I had to get that out of my system. Now for the real stuff: to understand RAG, we have to understand LLMs, so that seems like a good place to start.
🤔 What’s a LLM?
A Language Model (LLM) is a form of artificial intelligence that has the capability to comprehend and generate text by recognizing patterns from training data. LLMs operate by taking a sequence of words as input and predicting what comes next. To accomplish this, they assign likelihood values to potential outcomes and select the most probable.
ChatGPT is one such advanced model that utilizes a few different learning methods:
Supervised learning relies on labeled datasets to train algorithms, ensuring that models can make accurate predictions by learning from examples.
Reinforcement learning is when a model is fine-tuned based on the feedback it receives. This allows the model to continuously improve its responses and decision-making processes.
As we’re all aware, these learning methods have produced some astounding systems that seem almost human-like. Yet, when considering bespoke use cases (those outside of the training set), there are a few issues.
😱 The Problem with LLMs
Well, there are actually three:
LLMs are limited by the training data they have access to. If you can remember wayyyyy back to last year, ChatGPT was only trained on web data through Sept, 2021. That problem has already been solved, but it speaks to a larger problem: LLMs are fundamentally limited by their training data. That which is omitted from training data is outside the scope of the model, leading to our next issue…
LLMs are generic. You can't ask one where you left your keys... or how to do that really specific thing for your job.
Lastly, in most models, there isn't a reliable way to return the exact location of the text that an LLM retrieved information— that is, citation doesn't always work.
So you might be thinking, "ok, well how can I get an LLM to have access to my data... Can I just build my own?" Well... The issue is that these models require massive amounts of data, especially for an understanding of human language, so without an extra $80k to $1.6m, we wouldn’t recommend it.
And really, that’s a bad idea because there are already some great models out there... Like ChatGPT, Bard, Claude, & LLaMa (personally, I love the diversity in model names).
So what we need is a way to piggyback on the hard (and great) work done by those who came before us, but to augment our own systems with data specific to us.
That way, we avoid the costly headache of building and maintaining an LLM while reaping the benefits of having highly-specific context with a chatbot that understands human interaction.
🦸♂️ RAG: The Hero We Need
Enter RAG, the ability to retrieve additional information and augment the responses generated by our models, also known as Retreival Augmented Generation… Neat, right?
RAG combines three systems:
A dataset that contains domain-specific knowledge,
A retriever that finds relevant information in the dataset,
A generator that creates text responses based on retrieved data.
When input is provided, the retriever performs a "maximum inner product search" (MIPS) to find the most relevant documents/nodes. That information is fed to the generator to create a response.
This solves all of our problems with LLMs... it unlocks specificity, citability, and unbounded datasets! We're using the power of a massive LLM with intricate knowledge of the world + human language (e.g. ChatGPT) to answer questions about our own document stores.
It's the best of both worlds— you don't have to fork out millions and years to develop a model, but you can reap the benefits!
Developed by a research team at Meta in 2020, the academic description of RAG is incredibly technical— you might be able to see the process we just described in the following diagram from their paper:
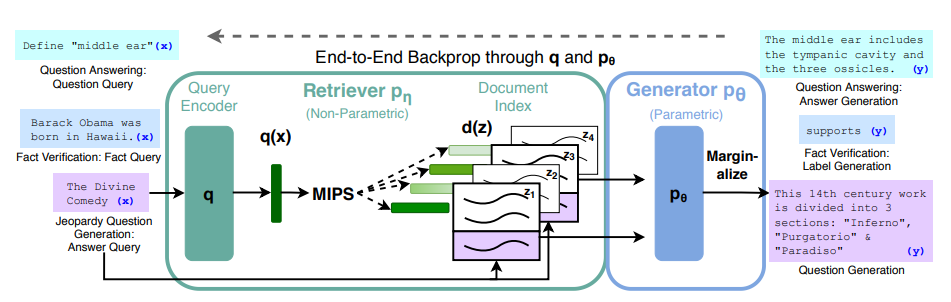
But breaking it down, we can arrive at the following one sentence definition of RAG:
RAG is a search of context-specific documents that grounds an LLM's response in relevant information.
Grounding is the process of anchoring LLM responses to highly specific information— it's crucial for ensuring quality and accuracy in LLM responses. RAG is a popular way of grounding information in AI apps, drastically reducing “hallucinations” from the model.
With RAG, you’ll be saying “wow” every time
🙋 What’s Next?
So, the question becomes "how do we store and access relevant data?" That is, how do we build & define the document stores & retrievers?
We'll save that for another post, but the short answer is vector databases and custom retrievers... Until next time! ✌️